
今回は現在、一般的によく使われているリレーショナル・データベースについて紹介します。
リレーショナル・データベースの概念
1970年にIBMのE.F.Codd氏によって提唱されたリレーショナルデータモデルの理論に従って作成されたものがリレーショナル・データベースです。
リレーショナル・データベースは、管理する項目を列(column)、内容である要素を行(row)として管理するデータベースです。
次に簡単な例をあげて説明します。
| 行 | 社員番号 | 名前 | 性別 | 部署コード |
| 1 | 010 | 田中一郎 | 男 | 0101 |
| 2 | 020 | 山田二子 | 女 | 0201 |
| 3 | 030 | 松本三郎 | 男 | 0301 |
この例では、社員番号、名前、性別、部署コードという4つの項目を持つデータベースで、現在は、
010, 田中一郎, 男, 0101
020, 山田二子, 女, 0201
030, 松本三郎, 男, 0301
という3つの要素を持っています。
このようにリレーショナル・データベースのこうぞうは非常にシンプルで、理解しやすいものなのです。
データベースはデータを単一で利用するのではなく関連するデータと連携して利用することがとても重要です。
次に連携の仕方について説明しましょう。
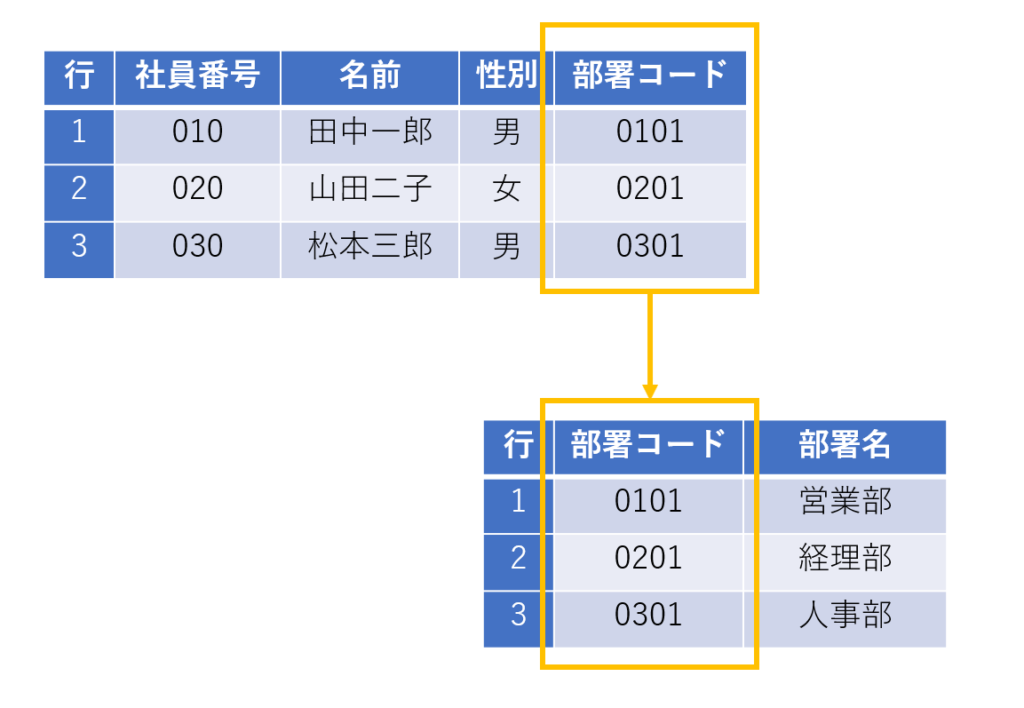
このようにデータが連携することで田中一郎さんが営業部であることが分かります。
このようにリレーショナル・データベースでは、データの連携をデータ項目(列)により行うことができます。
リレーショナル・データベースの特徴
リレーショナルデータベースには、以下のような特徴が挙げられます。
① 構造が単純
上で説明したように、行・列の2次元で構成される単純な構造になっています。
そのため簡単に理解でき、管理しやすい構造となっています。
階層型データベースとは異なり、上下関係や順序性もありません。
② 情報間の連携が簡単
列同士を結合することで情報間の関係が作れるため、たくさんの関係を作ることができ、複雑な情報連携が可能です。
列同士で関係が構築できるので、ネットワーク型データベースよりも管理が簡単になります。
③ 物理構造と分離されている
リレーショナル・データベースでは、物理構造を意識せずに利用することができます。
必要な行と列を指定するだけで、 物理的な位置やレコード中のバイト位置などは考慮せずに情報が取り出せるのです。
④ 平均的なパフォーマンスを提供できる
階層型データベースでは、専用のアクセスパスを持つ場合はとても速く、持たない場合はフルアクセスが必要となるためとても遅くなります。
それに比べ、リレーショナル・データベースではどのような条件であってもほぼ平均的なパフォーマンスを提供できます。
⑤ 「SQL」が使える
これが最も大切なポイント化もしれません。
「SQL」とはリレーショナル・データベースを使うために作られた言語です。
この言語が使えるという点が、リレーショナル・データベースが最もよく使われる所以でしょう。
